In the previous lesson, I have talked about IEnumerable and IEnumerator, and how they help us when we need to iterate over collections of data. Let’s take an example that deals with those concepts:
[raw][/raw]
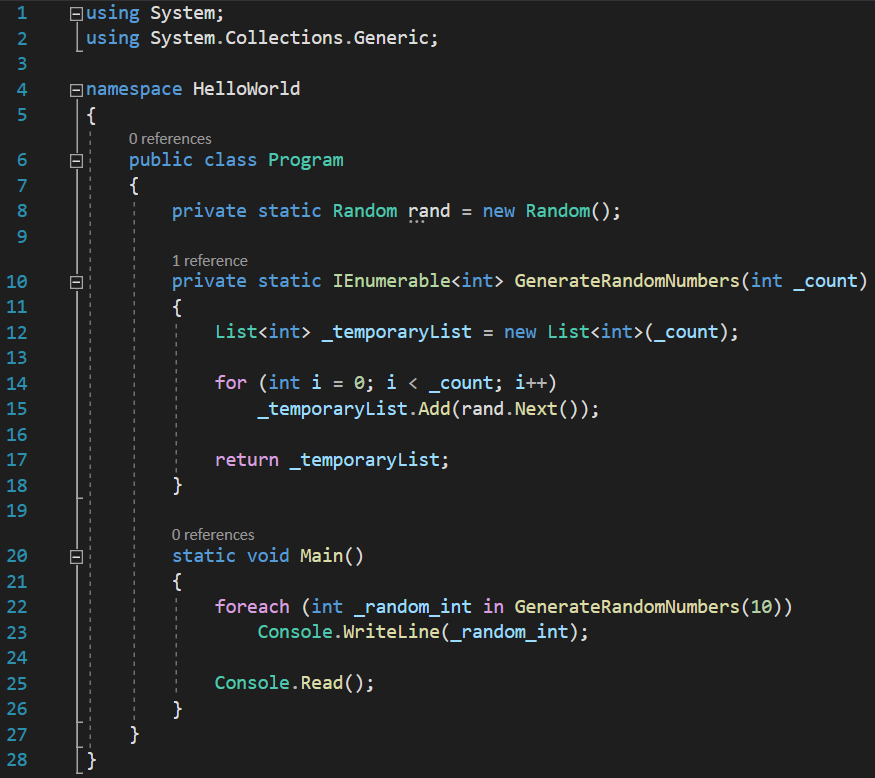
We have a function, GenerateRandomNumbers(), inside which we declare a List of ints, generate a number of random ints, equal to the _count parameter, add those random ints to the list, then return the list. In the Main() method, we simply iterate through the elements returned by that method, and display the results on the console.
The result is this:
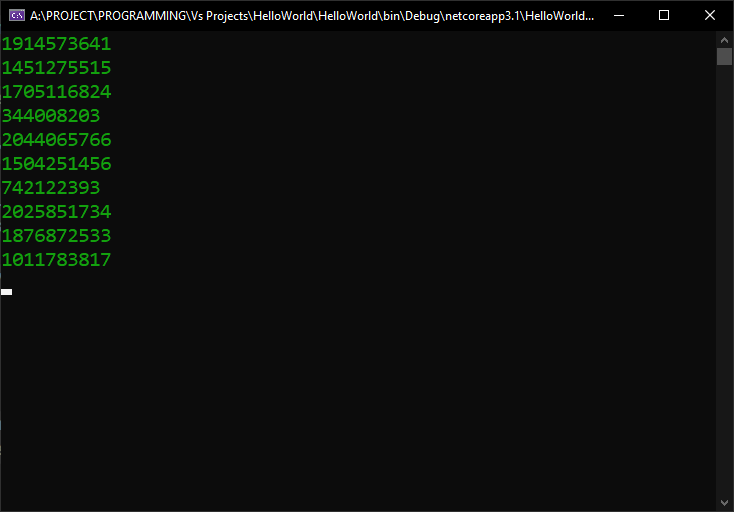
The problem with this approach is that we have first to allocate memory for a list, then we have to add items to it, then return the entire populated list, and we have to wait for the entire list to be populated before we can access the results, etc. Seems rather clunky, isn’t it? For this purpose, Microsoft added in C# 2.0 what programmers call iterator blocks, which are functions built to return either IEnumerable or IEnumerator in their generic or non-generic form, using one or more yield statements.
To get started in explaining this concept, let’s convert the same code from above so that we use the yield statement:
See code changes
Legend:

[/raw]

You can see that I no longer use a list, which is already an improvement. If we start debugging, we will get to this point:
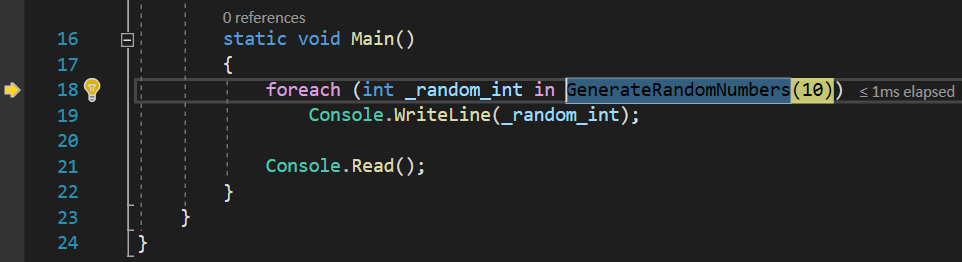
But, if you press Step Into or press the F11 key at this point so that the debugger continues to the next point of the execution, you will notice that, unlike your expectations, it will not even get inside the GenerateRandomNumbers() function, as it should. I mean, if the execution is paused at the point where we invoke that function, the next logical step would be to see it jump inside that function, in order to fulfill the call:
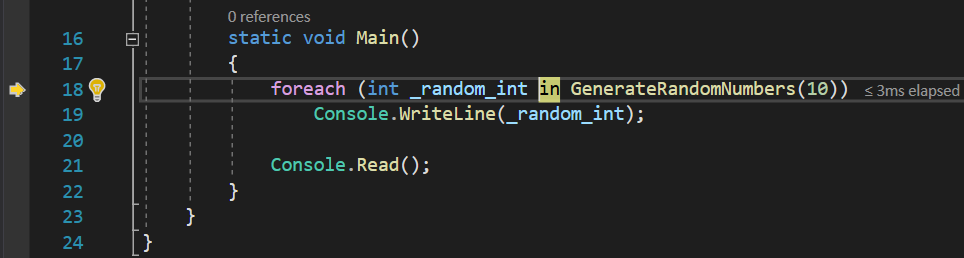
Doesn’t look like it does, is it? So, why is the compiler refusing to execute that function, and what does it even mean by going to the in keyword? Only when we press again Step Into, it will get us there:
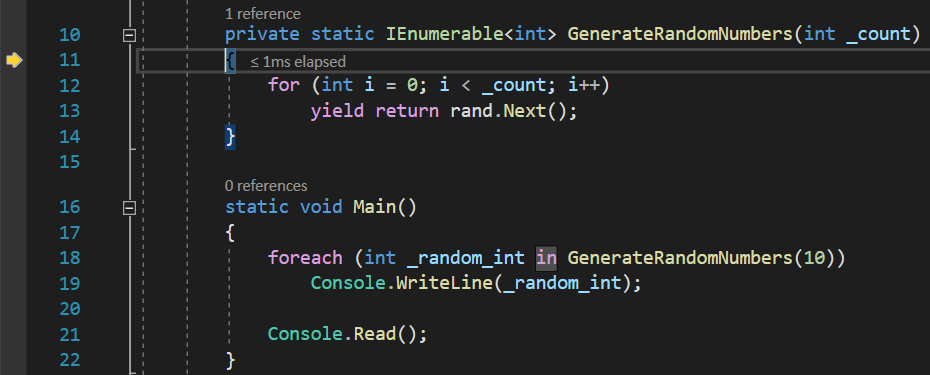
Not only that, but knowing that the return operator should immediately return a value from our function and return the execution to the code that invoked the function, you will be even more surprised to notice that it actually continues to move back and forth between the function caller and the callee several times, 10, to be more precise. In addition to that, you will notice that the execution will return to this point:
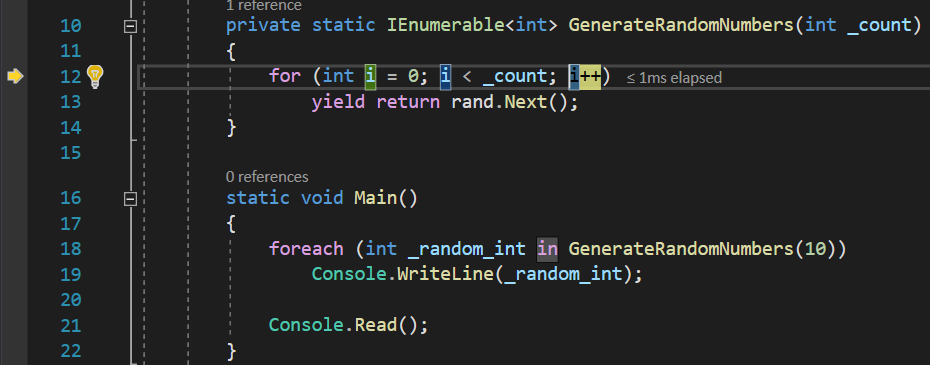
Which means the compiler not only jumps back to the GenerateRandomNumbers() function, but it jumps back directly to incrementing the control variable of the for loop, continuing the iteration from where it left of in the previous cycle! It is as if the compiler saves the function’s state, in a way.
So, the short summary of this lesson is that you can use yield return when you want to consequently return more than one value from a function, over the span of several function calls. For those of you who want to understand how the compiler accomplishes that, and how it works, let’s continue by looking at the generated assembly with a tool called ILSpy, which we already used in some previous lessons. This tool allows us to see the code that the compiler generates from our codes, either in C# or MSIL (Microsoft Intermediate Language).
The Main() method looks exactly the same:
But if we navigate to the GenerateRandomNumbers() function, we get this:
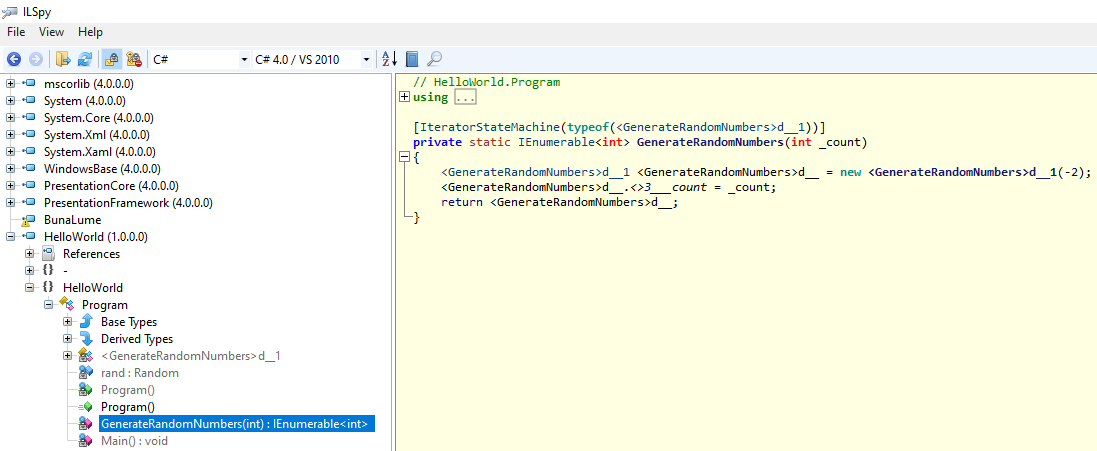 and we can notice it looks quite different from the codes we had in our program. You can see the use of the new operator, which indicates the instantiation of a class named <GenerateRandomNumbers>d__1, which may look kind of weird for a class name, since we are not allowed to use special characters such as angle brackets in the name of classes, but that is perfectly valid for the compiler. Navigate to this class, and you will see something familiar:
and we can notice it looks quite different from the codes we had in our program. You can see the use of the new operator, which indicates the instantiation of a class named <GenerateRandomNumbers>d__1, which may look kind of weird for a class name, since we are not allowed to use special characters such as angle brackets in the name of classes, but that is perfectly valid for the compiler. Navigate to this class, and you will see something familiar:
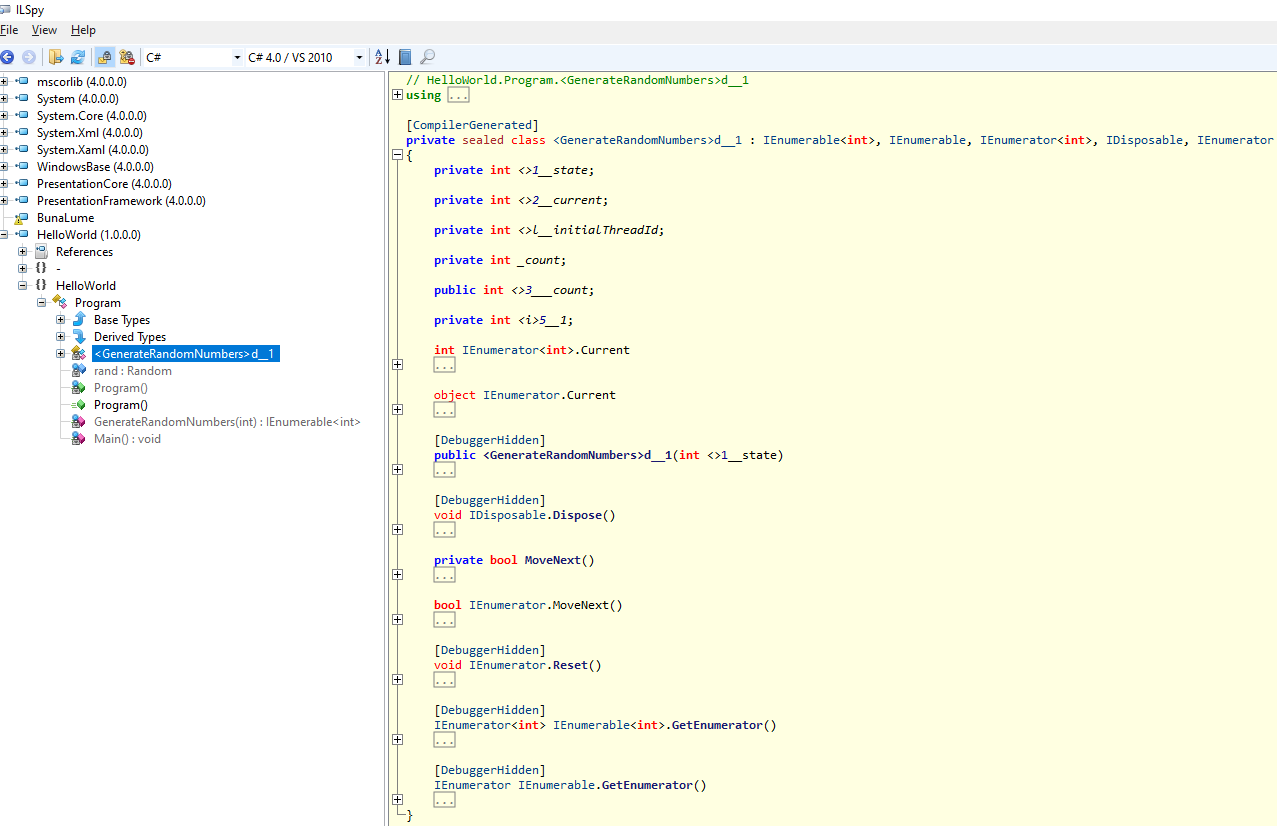 How convenient! This class implements IEnumerable and IEnumerator interfaces! And the MoveNext() function looks like this:
How convenient! This class implements IEnumerable and IEnumerator interfaces! And the MoveNext() function looks like this:

It is pretty obvious that, while we only use a simple yield return statement, there is a huge load of syntactic sugar involved beyond the curtains. Let’s try to retrace the same processes that the compiler does, in order to create our own version of iterator block. First, we get rid of the yield return instruction and we return a class instance, as seen already:
See code changes
Legend:

[/raw]
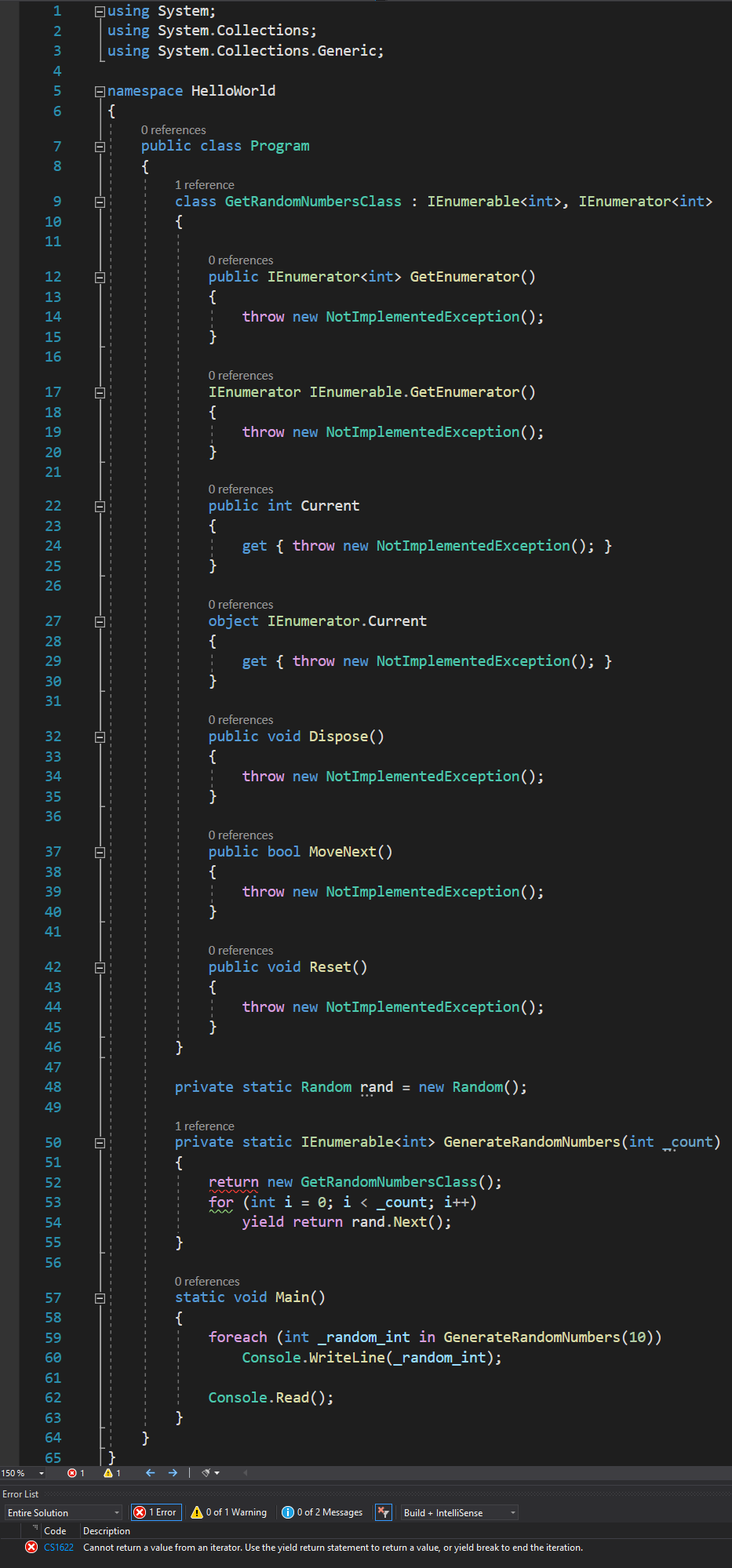
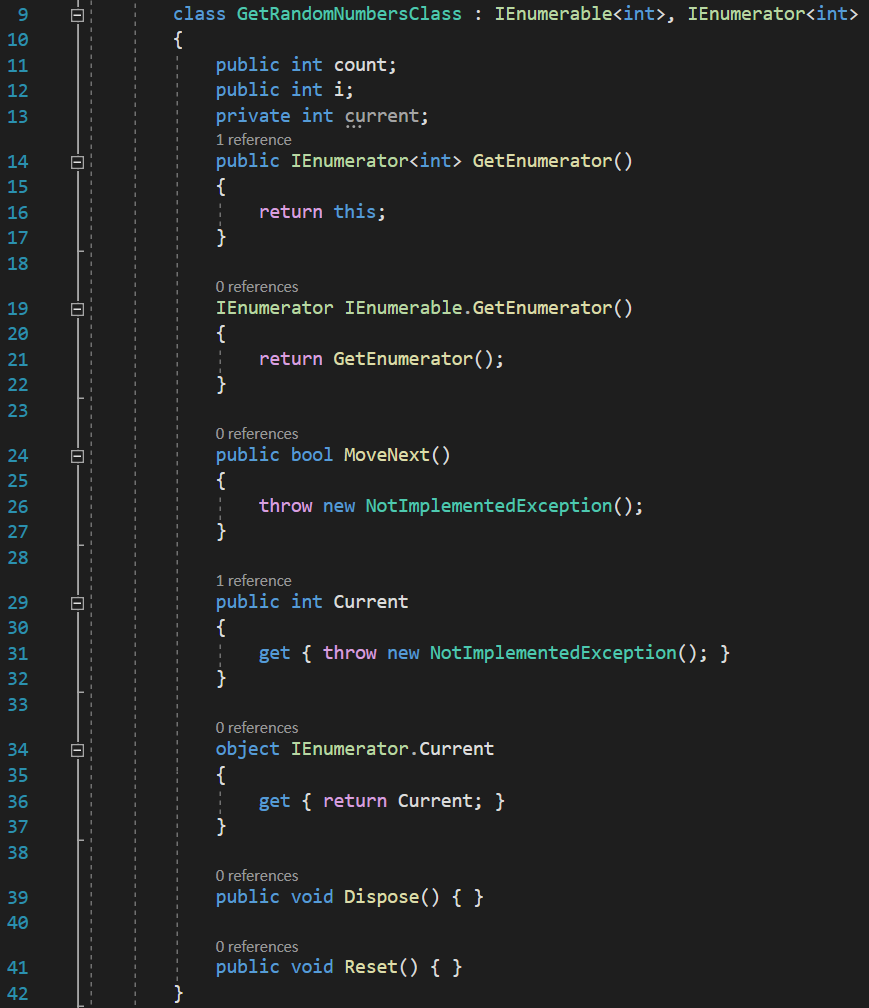
At this point, I have only created a nested class called GetRandomNumbersClass (the compiler likes to maintain as narrow scope as possible, that’s why it would generate a nested class) and I have replaced the yield return statement with returning an instance of this new class. Of course, at this point, the code will not compile for a whole number of reasons, but we will correct that.
For my custom class, I have implemented the generic IEnumerable and IEnumerator interfaces, because that’s what the compiler also does.
The next step would be to start adding the codes for the interfaces members. From my lesson about IEnumerator you already know that the Reset() method is completely useless, so we will leave it as it is.
You can notice that the method IEnumerable.GetEnumerator() is returning a IEnumerator object, and if you’re like me, you can see that we don’t need to write code in both IEnumerable.GetEnumerator() and GetEnumerator() methods. They both return a IEnumerator object, so I can just return one from the other:
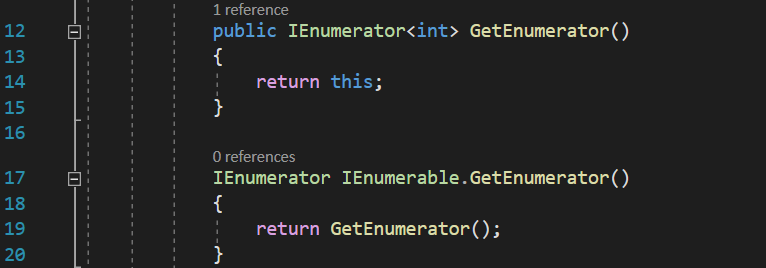
You might think that the GetEnumerator() I return would resolve to the IEnumerable.GetEnumerator(), thus obtaining an endlessly recursive call, but the call actually resolves to the non-explicitly implemented version of GetEnumerator().
You might also question why am I returning this from the non-explicitly implemented version of GetEnumerator(), and the answer is simple: my GetRandomNumbersClass class implements both IEnumerable and IEnumerator, which means that it IS not only an IEnumerable, but also an IEnumerator, which is exactly what GetEnumerator() needs to return.
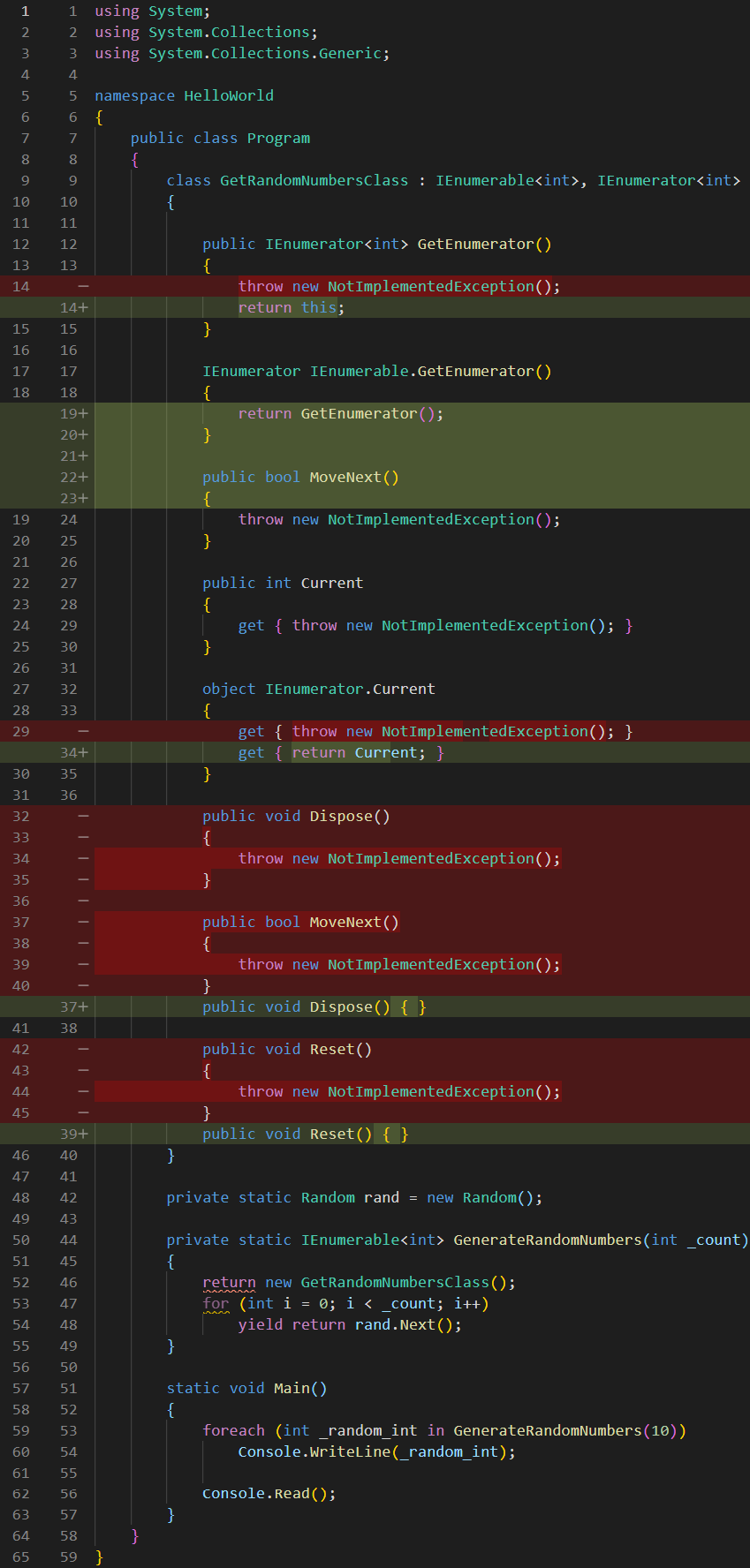
I am also applying the above trick to the Current and IEnumerator.Current properties and I will return the non-explicitly implemented version from the explicit one:
See code changes
Legend:
[/raw]

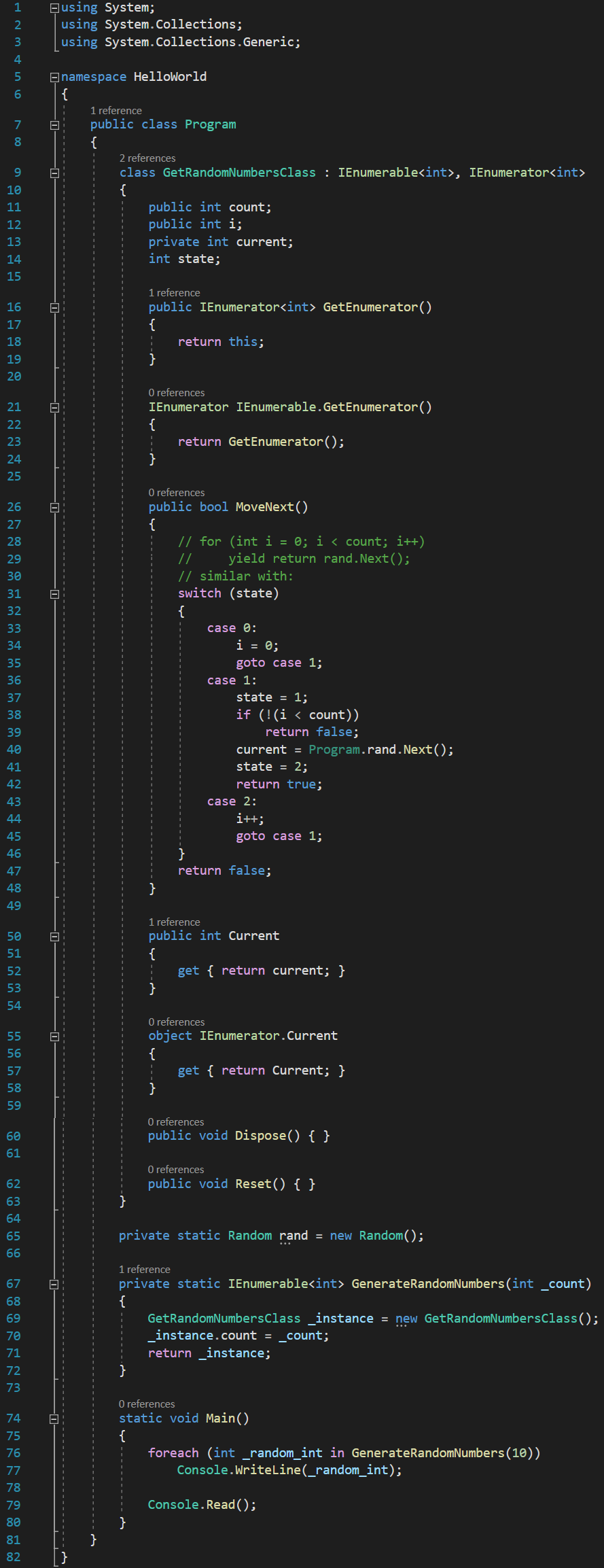
In this form, the next logical step is that our for loop somehow needs to end up in my MoveNext() function. If you think about it, every time I call MoveNext(), I’m really just saying “move next to the next random number”. Because of this, all the variables that I have used to construct my for loop need to end up as data members in my GetRandomNumbersClass. So, what variables are there in my loop? There’s count and there’s i, and here I move them inside my class:
You might argue that I should also transfer rand to my class, since I was using rand.Next() in my for loop, but in fact, I don’t really need to, since rand is defined as a class field member, and my GetRandomNumbersClass is a nested class. Remember that for nested classes, the inner class can access any member of the outer class. This is also the reason why the compiler creates a nested class.
Finally, I added an int variable called current, because, remember, current stores the current random number, and we need it for the enumerator block.
Next, we need to initialize the value of this current variable and I will do it by specifying it directly on the instance of GetRandomNumberClass that I am returning in the GetRandomNumbers() function:

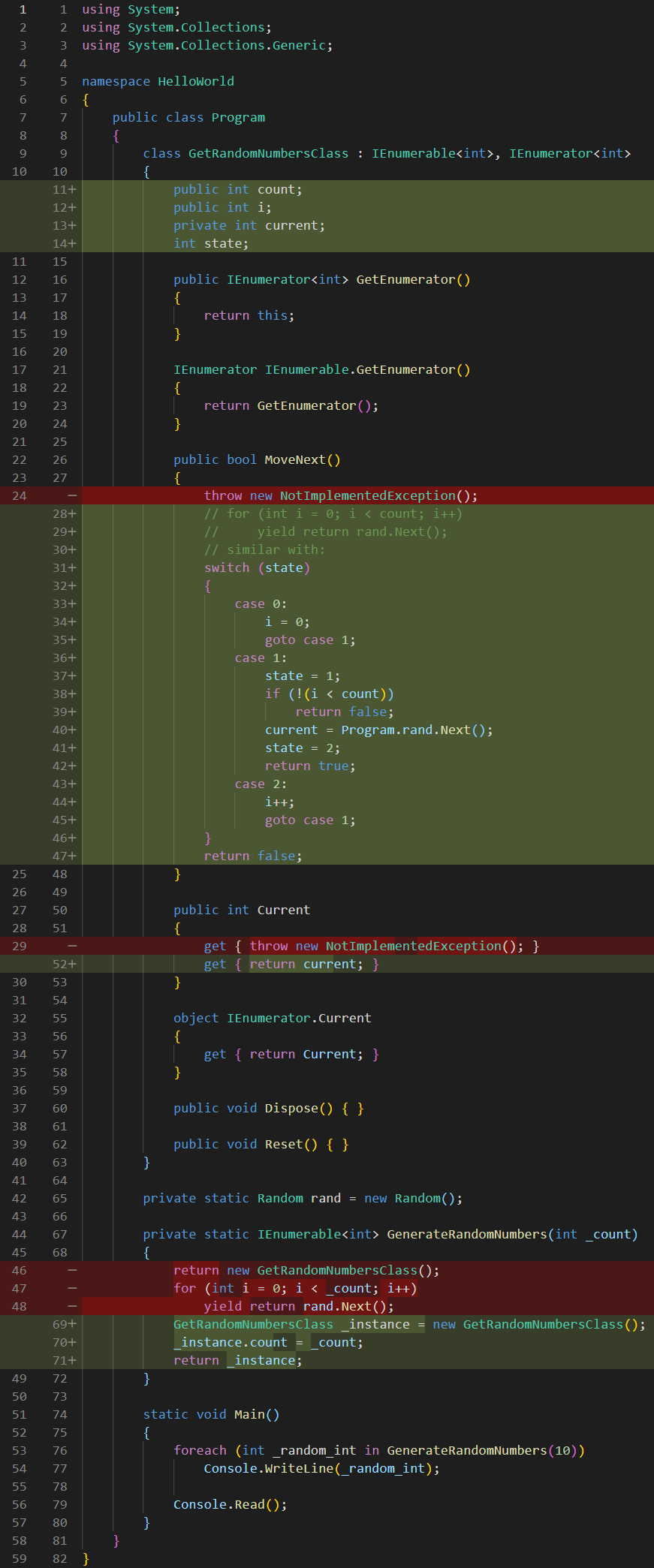
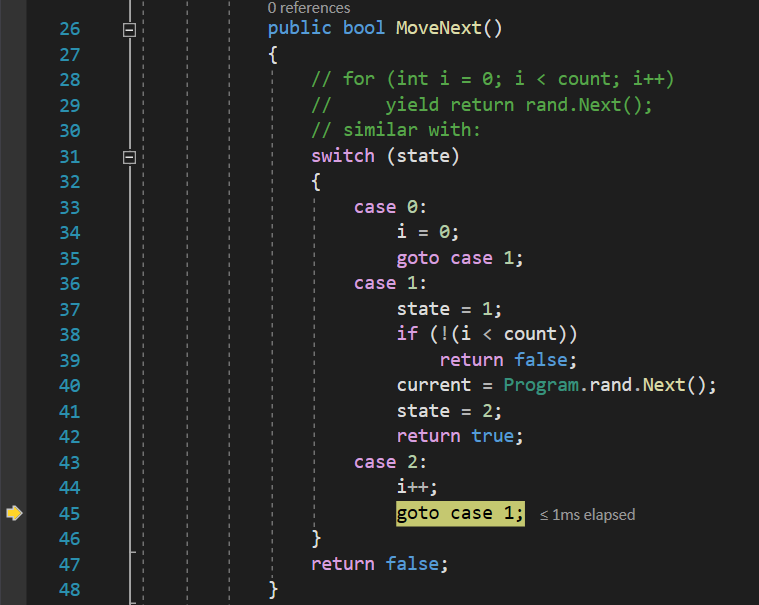
At this point, I am also ready to move the body of my now defunct for loop inside the MoveNext() function. For this to happen, I need to add another int variable named state, which the compiler actually uses to keep track of what happens when (for instance, in a for loop, the control variable is set to 0 only once, it is only incremented afterwards, etc):
When the compiler calls into MoveNext(), it basically turns a little bit into a switch statement, so that it accommodates this state variable:
See code changes
Legend:
[/raw]
Notice that in the MoveNext() function I added a commented code representing a for loop that yields results, which we previously used. This is so we can have a reference to what the MoveNext() function should be doing. Now, let’s analyze step by step what we did in the MoveNext() function: after creating the switch statement for the state variable, we added the first case, when state is 0 . This is ran a single time, when the foreach iteration starts. Therefor, here we initialize the i variable to 0 too, so it has a reset default value, then we tell the compiler to goto case 1. This is because we also need to return a first value of the iteration. Think of this case 0 as the for (int = 0; … part of the for loop, where we declare and initialize the control variable.
In the case 1 part of the switch, we need to implement the for (… i < count; … part of the for loop. Thus, the first thing I do is check if i is equal to or greater than count, in which case I return false, to end the iteration.
Aside of that, I am also setting the value of the state variable to 1, so that the next call to the MoveNext() function will resume from case 1, and not run case 0 again, where it would reset the value of i.
At this point, we are not going to increment i, because, remember, a for loop first initializes the control variable, then checks the ending condition, then runs the code in its body, and only AFTER that, it increments the control variable. So, after we do the ending condition check, we need to implement the body of the for loop, and what does that body contain? The yield return statement.
Of course, that actually means returning the value of the Current property, but, remember, we can’t do that, because the MoveNext() function returns a boolean value, indicating whether the iteration continues or not. Since we cannot return the actual value of the current iteration, we need to assign it to the current backing field of the Current property. Of course, what we need to assign to it is a new random value, and we get that random value from the parent class of our GetRandomNumbersClass inner class using the rand variable declared inside it, and calling the Next() function on it.
After that, I need to return true, to indicate that the iteration can continue. But, before that, remember, what does a for loop do after it runs the code in its body? It increments the control variable. To emulate that, I added a case 2 to the switch, in which I am incrementing i. This is similar to the for (… i++) part of the for loop.
To make sure the execution gets to this case the next iteration, before returning true, I am setting the state variable to 2.
Finally, after incrementing the control variable, a for loop re-checks the ending condition, and if true, it re-runs the code in its body. Well, we have that part in the case 1 of the switch, so, after we increment i in case 2, we use a new goto, to jump to the case 1 code and execute these codes again.
At the bottom of the MoveNext() function I also added a return false; instruction just to make the compiler happy, though the code is written in such a way that it should never be executed. The Current property just returns the current backing field variable.
And that is all there is to it. I should now be able to run my custom implementation of a yield return, so let’s check it out. We start the program in Debug mode by hitting the F11 key, and when we advance to the foreach loop, we will see that it will get to the GenerateRandomNumbers() function:
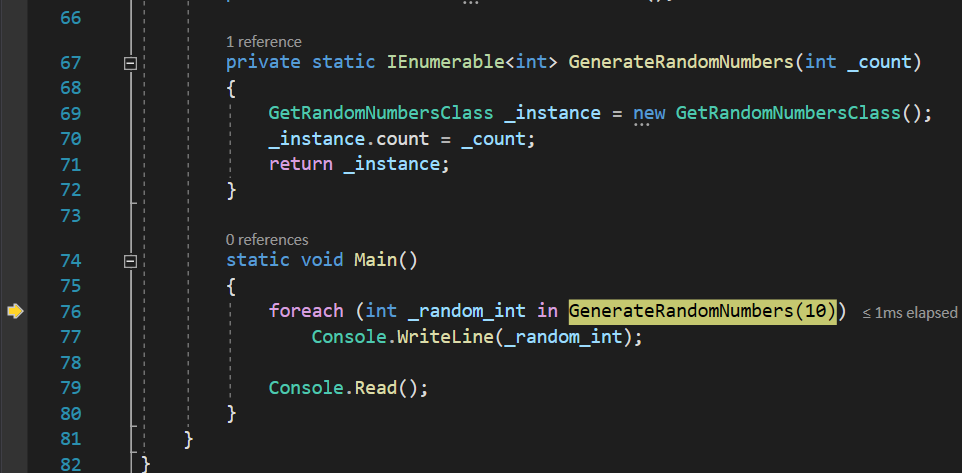
Inside this function, we instantiate a new GetRandomNumberClass instance, and we set its count variable to 0. We also return this instance, since the GenerateRandomNumbers returns an IEnumerable, and GetRandomNumberClass implements it:
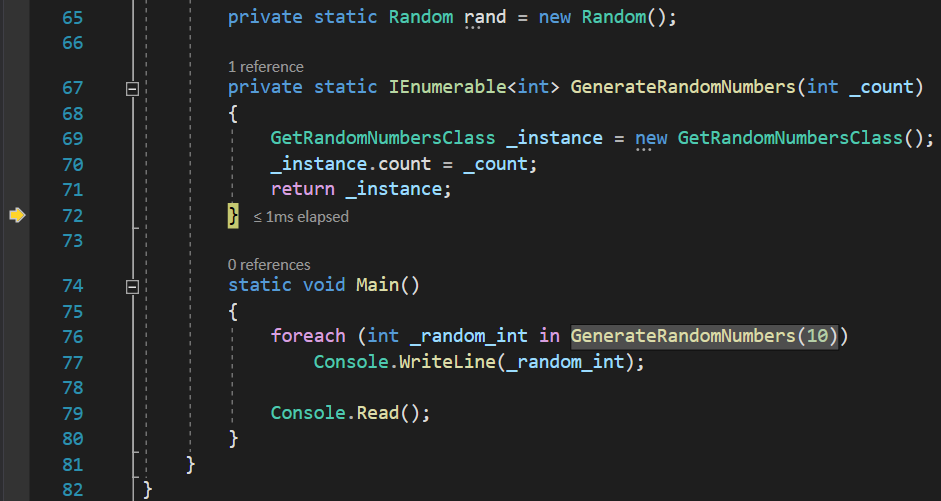
Since class GetRandomNumbersClass implements IEnumerable, it is also an enumerator. Therefor, it will jump inside the GetEnumerator() function, to return it:
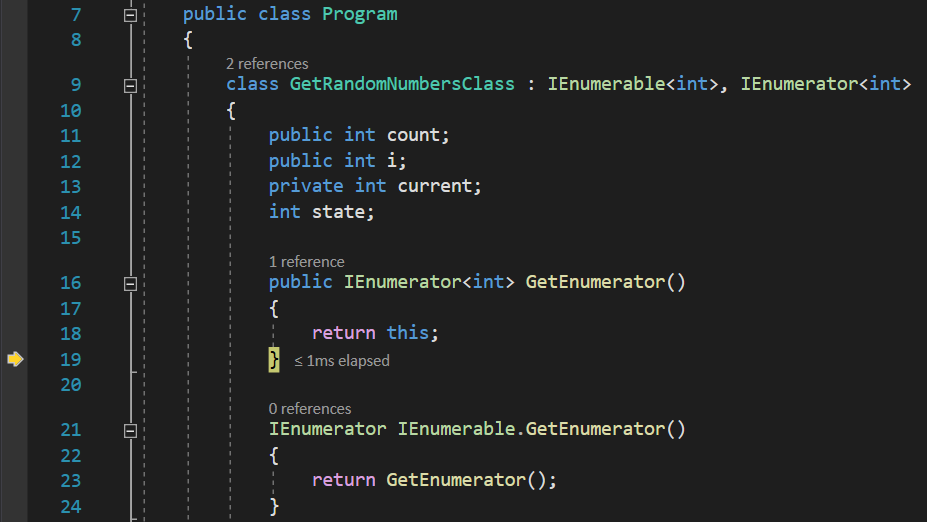
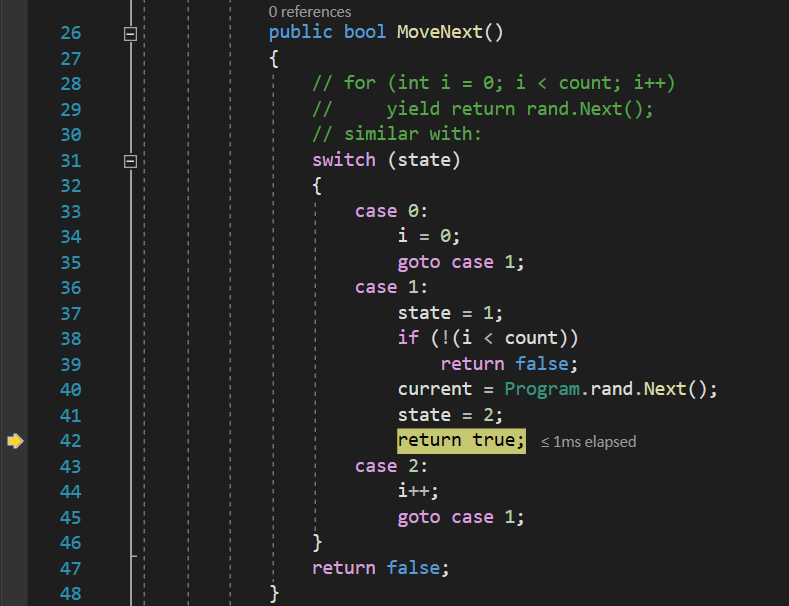
Next, when it gets to the in keyword, the enumerator will call the MoveNext() function for the first time. Since inside the MoveNext() function we switch the state variable, and since its value is 0 at this point, the case 0 part of the switch will get executed, where we initialize i to 0 and transfer the execution to case 1:

Inside case 1, we make the check to see if the loop ending condition is met, then we set the Current property to a new random value, we set the state variable to 2 so that the next call goes to the control variable incrementation part, and we return true, so that the iteration continues:
At this point we do get a random number printed at the console:
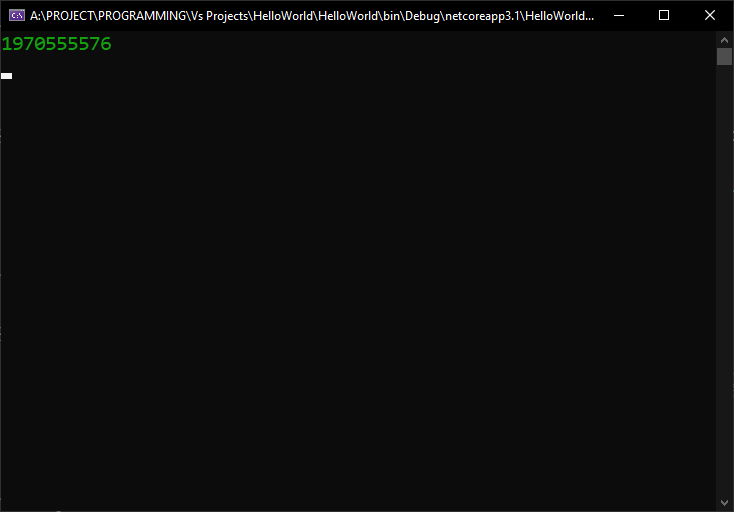
And the execution goes back to the MoveNext() function, for the next iteration. But, since last iteration we set the state variable to 2, the execution goes to case 2 of the switch, where we increment i, and only then we jump to case 1, where we return a new random value:
There are a few things to keep in mind when using the yield keyword in your codes:
- do not use yield in an unsafe block.
- do not use ref or out keywords with the parameters of an iterator block method, operator or accessor (getter/setter).
- yield return can only be placed in the try block if it is followed by a finally block.
- yield break can be put in the try…catch block, but not in the finally block.
- do not use yield inside anonymous methods.
In the next lesson, I will write about the yield break operator, which we can use to stop yielding results in a iteration.
Tags: foreach loop, IEnumerable, IEnumerator, iterator block, yield, yield return

